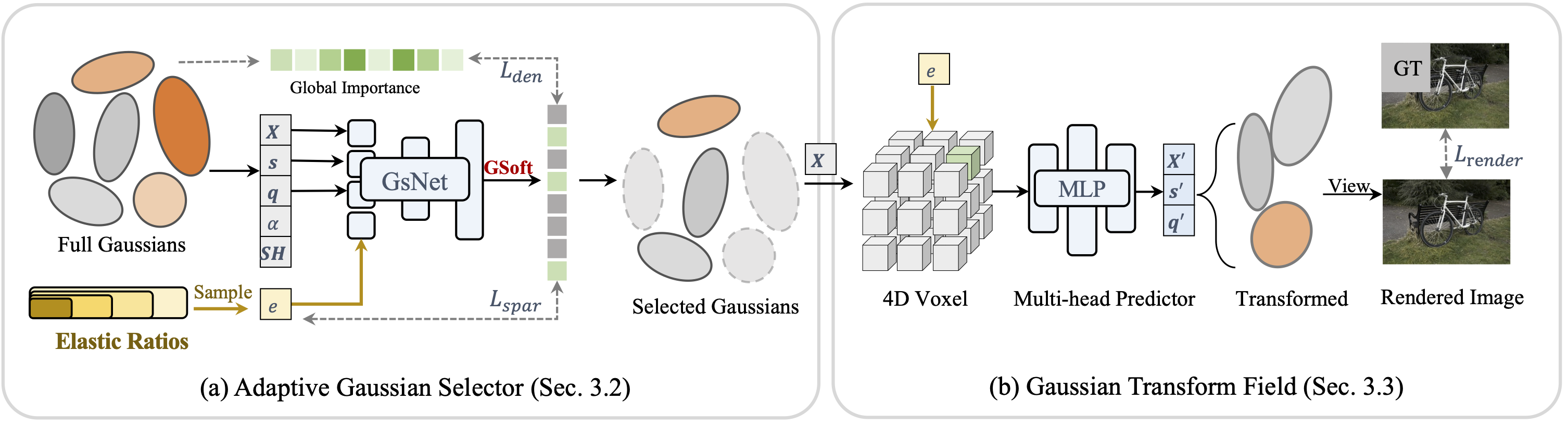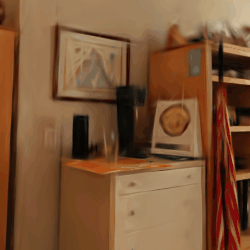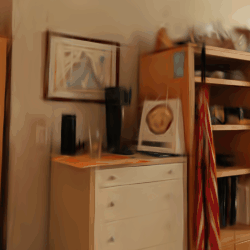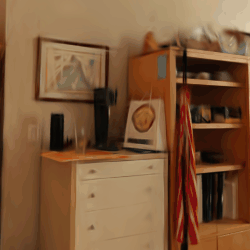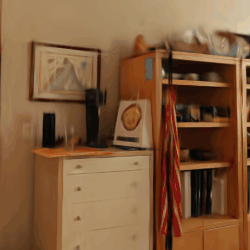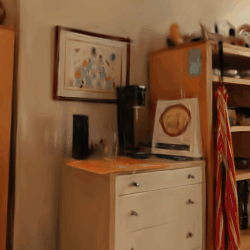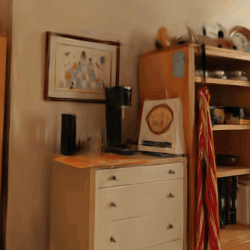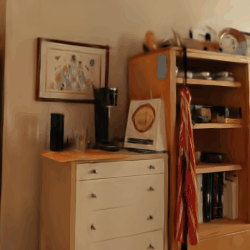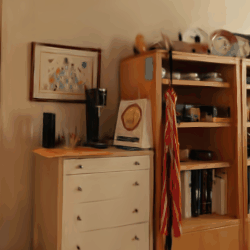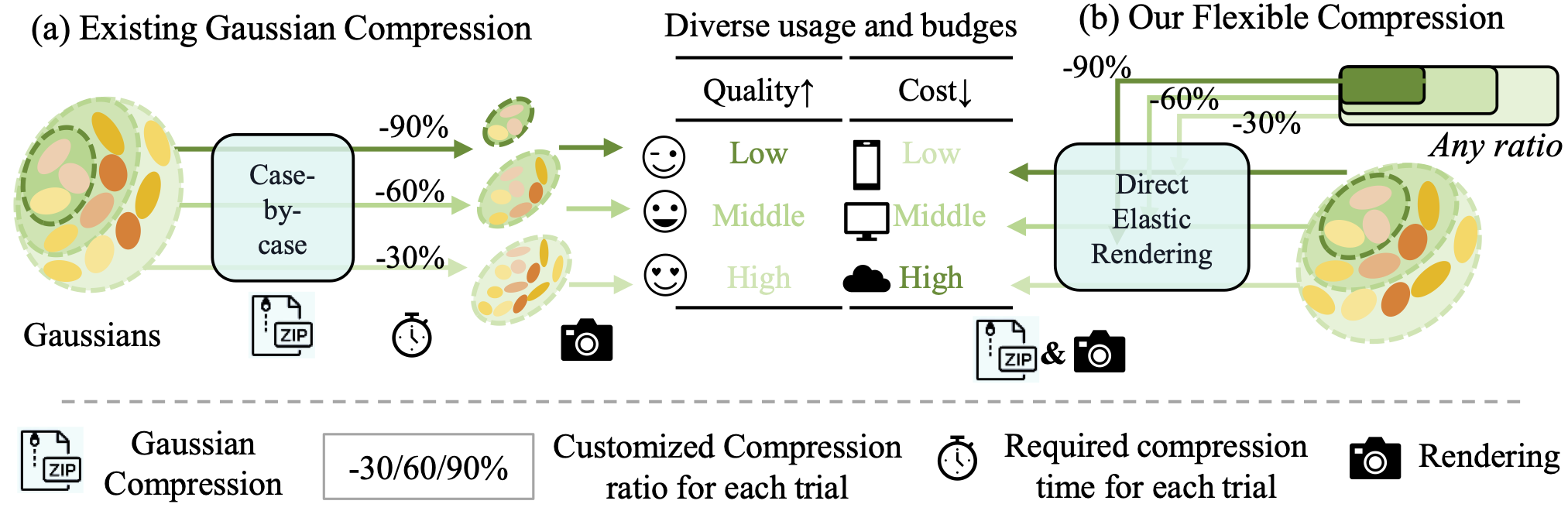
Compared to post-processing methods that require ratio-specific fine-tuning, such as LightGS, FlexGS can infer the selection and transformation of Gaussians for any given ratio without the need for re-training. This enables flexible deployment scenarios, like web, smartphones, PC, etc., at arbitrary compression ratios.